I’ve been diagnosed with an ‘ugly’ prostate cancer. It’s a simple, hard and unavoidable fact, and it is nothing to try to hide or escape from. So, there is nothing else to do than to take out the somewhat cynical perspective on life I’ve inherited from my father. I will therefore not delve into a sad story full of pitying and negativity. If I cannot change something, I can just as well observe what happens and learn from it. And then I can share my thoughts about everything that happens around me, as I will do in this post. Here I will describe my experiences as a combined patient and HMI researcher from the first of a sequence of in total twenty-nine days of two minute radiation treatments. And there will of course be one “conclusion” of my experiences at the end of the post (although, it might not be what you expected).
The treatment of prostate cancer has taken huge steps forward over the years, and I’m not as scared as I probably should have been fifteen or twenty years ago. “Cancer” is still a scary word, and we don’t talk about it in the same way as we talk about a flu or maybe more accurately about having a pneumonia. But I will try to look away from the scariness, and go into “observation mode”. And here is what I have observed:
I enter a large bright room with soft music playing. First I remove my trousers and any electronic devices (for example, my smart clock). At the center of the room is a plastic monster, looking as if it came directly from the stage of Star Trek (see the picture below). The contraption holds a rotating radiation gun and an X-ray machine that work together to focus the radiation. The process uses X-ray triangulation of three gold grains, (actually miniature strips of gold leaf) that have been operated into my prostate, to make sure that the radiation beam is aimed correctly each time.
A painting of the room for radiation treatment with the “radiation gun” in the background (AI-generated picture by the author and Dola AI).
I am placed on a steel bed, with some ergonomic supports for my legs. With a number of laser beams, my three “tattoos” (small, andactually tattooed dots on my hips and tummy) are aligned with some positional markers. The bed is adjustable in many different degrees of freedom, to make it possible to reach the “perfect” position for the treatment. The nurses leave the room and the whole contraption with radiation head and X-ray machinery starts to rotate around my body, with short stops. making the final positional adjustments before the radiation is started. Finally it makes two full circles back and forth with a special, strange buzzing sound. I assume that that is the radiation phase.
And I don’t feel anything at all. The huge machine in the picture focuses the intense beam to precisely hit the small ‘dot’, smaller than a pea, that is the main character in this drama. The beam goes through a 360° rotation around me on the bed. It’s a very narrow but strong beam, invisible, but not at all harmless. And … I feel absolutely nothing. After approximately two minutes of buzzing and the continuous rotation of the radiation head, I’m ready to get up and go home again. No pain, no itch, no feeling of heat. But two minutes of high-energy photons (or electrons?) have made their impression on my non-wanted part of the body.
But as I lie there on the bed, I immediately start to think about the amazing computer system that handles this process from beginning to end. All the preparatory X-rays, alignments, calculations, and the careful dosages given by the machine are (of course) all handled by computers. And, I hasten to add, by the professional team they serve. It is even really mindboggling to think about the creation of the complete system of Human-Machine Interaction that allows for these (and many similar) tools to be used at hospitals all over the world.
But… it is also when I lie there, the machine buzzing and rotating that I get this very insisting thought that penetrates my thoughts:
AND THEN WE HAVE… COSMIC…
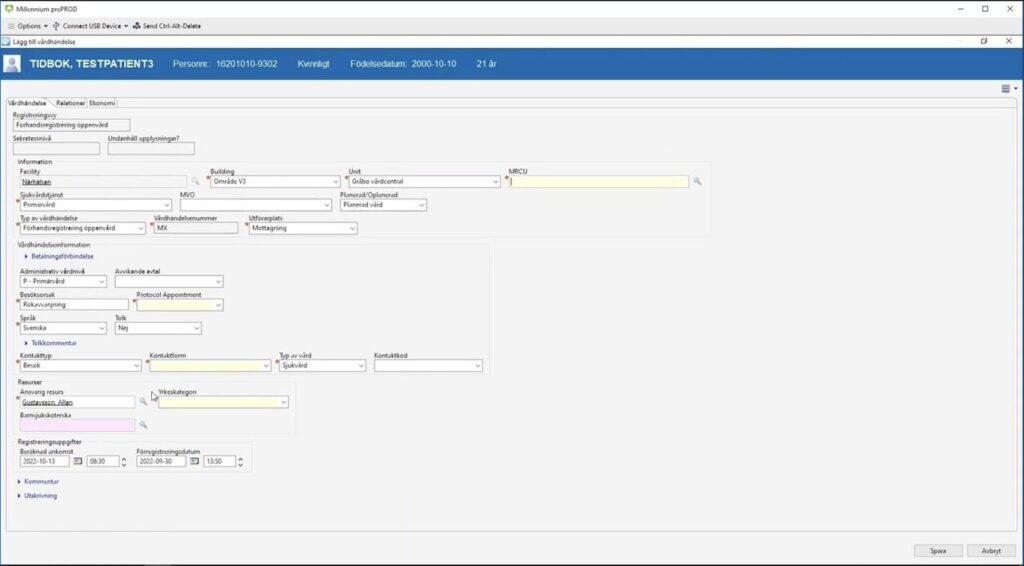
A real screenshot, actually from the Mil***nium system (I could not find any suitable screenshot from COSMIC.)
The contrast is on the brink to being hilarious, were it not that the topic is so serious and that people really have to work with COSMIC (I will not be so macabre, as to say… mi***nnium, but i guess you already thought about that?). Why, oh, WHY can we make such fantastic medical systems as the radiation treatment beamer, and then fail so miserably in making such an essential, “has-to-be” simple system for the storing of patient data?
WHY? OH, WHY?
POST SCRIPTUM: I have to give my full praise to the personnel on the clinics for radiation treatment and urology, who have been so wonderful and supportive in this difficult situation. Always happy and personal, providing a very large feeling of safety and comfort. Thank you, and I wish you could have a more friendly system than COSMIC at your workplace.
En gång i tiden var chefer personer som visste allt om det jobb de chefade över. Idag är chefer ofta anställda för att de är “duktiga chefer”, och inte nödvändigtvis för att de har god kunskap om hur verksamheten bedrivs på “gräsrotsnivå”. Resultatet kan bli orealistiska krav på prestation, produktion och resultat, i värsta fall också kombinerat med dålig kontakt med sina aktiva medarbetare. En chef som inte vet hur man utför grundarbetet riskerar dessutom att förlora sin nödvändiga pondus. Jag ska exemplifiera vad jag menar med följande anekdot från verkliga livet:
Min far kom 1958 från Tyskland till Bergianska trädgården som praktikant och sommarjobbare. I början fick han gräva rabatter och rensa ogräs, precis som alla andra praktikanter, efter att ha gått en grundutbildning på en trädgårdsskola. Efter ett år på Bergianska trädgården fick han anställning som trädgårdsmästare i Kalmar.
Han fortsatte sedan att arbeta som trädgårdsmästare på olika platser och i olika positioner. Till Enköping kom han år 1966 som stadsträdgårdsmästare, såvitt jag vet den första anställningen där han oftast var klädd i kostym, snarare än arbetsbyxor och flanellskjorta. År 1978 fick han anställning som chefsträdgårdsmästare vid … Bergianska trädgården i Stockholm. Cirkeln var sluten.
Den händelse som gjort ett av de största intrycken på mig inträffade en tidig sommar när jag besökte honom, och han just då visade runt en delegation från en japansk botanisk trädgård, klädd i kostym och slips. När de passerade några trädgårdsmästare som grävde en ny rabatt, blev han väldigt upprörd: “Så här kan det inte se ut. Det måste vara helt raka kanter, och det måste vara minst 40 cm djupt!”. Trädgårdsmästare svarade att “Det går inte, det är stenigt och jorden är stenhård!”
Min far svarade inget, tog bara av sig kavajen, tog spaden från en av dem och grävde en halvmeter… helt rakt och 40 cm djupt. Han lämnade tillbaka spaden, tog på sig kavajen igen och sa bara helt kort: “Sådär vill jag ha det gjort!”. Sen gick han vidare med sina gäster.
Den episoden sitter fortfarande gjuten i mitt minne, 40 år senare. Min far använde ett argument som det inte går att diskutera emot; han visade praktiskt att han visste vad han begärde av sina anställda. Han var alltså inte bara en teoretiker som aldrig hade tagit ett spadtag (trots att han gick omkring i kostym och slips). Han var en chef som visste hur det grundläggande hantverket skulle utföras. I min egen undervisning har jag alltid försökt att förmedla den här grundläggande tanken: som chef eller projektledare måste man åtminstone ha grundkunskaperna om det område man ska leda arbetet i. Man behöver inte vara expert, men man måste veta tillräckligt för att kunna uppfattas som en auktoritet i sin roll som chef.
Ska jag till exempel leda ett utvecklingsprojekt för ett stort datorsystem måste jag förstås kunna tillräckligt mycket om systemutveckling och programmering för att kunna veta om det är genomförbart eller inte, men jag behöver också veta tillräckligt mycket om det område systemet ska användas inom för att inse om systemet inte uppfyller användarnas behov. Har jag inte den kunskapen är risken stor för att jag kommer att:
misslyckas med projektet genom att ställa felaktiga, för svaga eller för hårdare krav på systemet
bli en chef/projektledare som kommer att sakna förtroende hos mina medarbetare, kanske till och med till den grad att jag blir gjord till åtlöje bakom ryggen.
Om man inte har de grundkunskaperna finns det förstås fortfarande en möjlighet att bli/vara en bra chef. Men då måste man istället vara ödmjuk och efterfråga de kunskaper man själv inte har, från de av sina medarbetare som har just den erfarenhet som man själv saknar (här kan man också behöva påminna sig själv om att det inte alltid är de med högst utbildning eller position i organisationen som har den bästa kunskapen om alla moment i arbetet, utan man kan behöva höra sig för med medarbetare från alla kategorier.).
Det som däremot inte fungerar är den omnipotenta chefen som antingen tror sig kunna allt eller, ännu värre låtsas kunna allt.
Den här texten tillägnas minnet av min far, Klaus Oestreicher, som hastigt lämande oss den 28 juni 2024 i en ålder av 90 år.
In the previous post I wrote about how we seem to forget most of our history, when it comes to failed projects. Some projects will create working conditions that are similar to working in a very messy kitchen, where the fridges have stopped working ages ago, but nobody has noticed. The sad fact is that we already know some of the factors that will cause a project to fail, and we even know them far too well for it to be comfortable. Ken Eason wrote about the problem already in 1988, and unfortunately it is still possible to recognize several of the reasons he lists in many of the projects that have failed since then. In the following, I will use numbers to denote examples from some of the later software engineering failures as follows:
Millennium (An administrative system for hospitals and other medical units, failed).
Blåljus (An administrative system for the Police, failed)
Moving from Mellior to Cosmic (Two administrative systems for medical administration in region Gävleborg, running but with large problems)
Ladok (A joint administrative system for the academic studies, students and examiners, running and works after many small and large problems)
Nationella proven (the central administration system for national correlation tests for the Swedish education, was recalled two days before the day of the test).
The failures in these projects point to different, but related problems in the development and introduction of the systems. This list is by no means complete, but these systems display some of the well-known factors leading to failures or inconveniences. The failures could be quite easy to predict from what we know about human factors and experiences from earlier failed projects. It would be possible to write long reports about the reasons for failures of all these projects, but here I will just try to highlight some of the most evident of these.
What is the purpose?
The main document that guides the software development process is the requirements specification, which is a huge document, supposedly describing the complete functionality of the whole system to such an extent that we should be able to program the system starting from that base. This document is also normally the base for the contract between the stakeholders in the process. If a function is not in the requirements specification, it is not supposed to be there. Adding functionality outside of the requirements specification is a big no-no, just as if the functionality described by the document is missing in the system.
This sounds both great and solid, but there are some caveats already in the beginning of the process. The first is to get an overview over the complexity of the specification. For larger systems, this becomes an overwhelming task, that most humans will no longer be able to perform. However, there are already software tools that will help in the process, and I assume that this will be a task that can be well supported by systems based on artificial intelligence technology, since summarizing texts is what they are already supposed to be good at. But more crucial is that the requirements specifications, despite their complexity, will often still be incomplete to a certain extent. What is missing? Quite simply, we often spend very little time finding out the purpose, or the goal, of using the system for the end users. We can specify the central functionality to the extreme, but if we don’t know what the goal of using a system is this will still not make the system well designed. In some cases, there are also unspoken, tacit and missed requirements that will affect the usability of the final system.
The Goals – Not the tools
To make matters worse, most systems today do not have one single goal, but many, and sometimes even contradictory. An administrative system for the health services has one very clear overall goal, namely to store all the information about the patients in a secure, safe and still accessible manner. We may also have quite detailed requirements on security, about which items to store and how they need to be stored etc. But, the question is, do the requirements show the purpose of storing the data? Let us take the following example:
“An X-ray picture is taken of the knee of a patient. If the only purpose of taking the X-ray is to document the treatment of the patient, it might not matter so much if the X-ray image becomes cropped at the edges to fit the standard image size when it is saved in the journal system (1). But if the purpose instead is to make a diagnose, some small details around the edges might be very important. If the details are missing, then in the best case the surgeon only needs to order a retake of the image, but in the worst case, the doctor might not know about the cropping of the image and miss vital information for the further treatment of the patient. It appears that the quality of the storage of the data becomes very important for the health professionals using the system.“
More diffuse, albeit, obvious goals of a system, may not even be mentioned explicitly in the requirements. We can, for example, be sure that one of the main goals of introducing a (new) system is to make the work simpler, or at least more efficient for the users. Thus, if a previously simple note-taking task now requires more than twenty interactions with the system, this is definitely not supporting this indirect goal (1, 2, 4). In Ladok, entering the final grade for a course now has to pass over at least five different screens, where the final step forces the examining teacher to log out from the system and then back in again. This is stated to be for “security reasons”. It is difficult to understand how this can be regarded as “efficient”.
Furthermore, most people today will use some kind of password manager to save login identities and passwords, so that you don’t have to remember the login data. With this type of program activated, the user only has to press “Enter” one extra time, and you are once again logged in again. Where is the security in this extra set of button presses? And what are the users’ goals and tasks in all this? Logging in one extra time is definitely not part of these.
Open the door, Richard!
To make the general discussion a bit more clear, let’s take a side track over a very simple physical example that most people should recognize: “The door handling mechanism!” Normally this mechanism is referred to simply as “the door handle” (but there may also be a locking part). But a door handle can have many different shapes, from the round door knob, to the large push bar that stretches along the whole width of the door. Which design is the best? Someone might argue that the large push-bar is the best, since it allows for the use of both hands. Some might instead hold the aesthetic design for utterly important, proposing the polished door knob as their favorite.
The discussion often ends in a verbal battle about “Who is right here?”, and commonly people who have the HCI education in their backs will reply with the ID principle: “It Depends” (the principle holds that there is almost never a single truth to the question but that there are many factors that we need to contemplate before the design). This principle is of course one way to look at it, but if we consider a kitchen door, for example, this may not be the best place to use a polished door knob (as any chef or cook would immediately realize). A hand that has been handling different kinds of food will often be more or less covered in grease or even some remaining soap after washing. This will in turn make a door knob impossible to twist. Better then to use a regular door handle with the Archimedes’ levering mechanism (which also provides the necessary force for people with weak muscles, of course).
However, maybe we should look a bit further than to the best specific design of the door handle? How often have you seen someone just standing in front of the door, only twisting or applying force to the handle? Isn’t there something further involved in the action? What is the goal of using a door handle? If we think a bit further, the goal of using the door handle is most of the time to open or close the door! Right! Now we know enough then? Well, know, how often have you seen someone just opening and closing a door just for fun? OK, some children might think it’s a good way to annoy the parents, but apart from that? What is the purpose for opening or closing a door? Of course, it’s to go to the other side of the door opening, or to close it in order to stop someone or something from coming in or out. So, this is in fact (very close to) the final goal of using the door handle, to get out of or into a room or at least to get through the door opening. So, any solution that will support a user to handle the door in a way that achieves this goal will be acceptable, and there may even be some solutions that are really good (and not just usable).
Back on track… to the rotten parts…
Now, I assume that nobody would really forget that doors have the purpose mentioned above, but for other tasks it may not be so simple. In some cases the goals of using a system might not be so simple and clear. Even worse, we might forget that the same system may have different purposes depending on the user and his or her perspective. The main purpose of a system may be one thing, but for the individual user, the main purpose of using a system may be very different depending on the user role, the assigned tasks and many other things. And here comes the big problem: while we most of the time construct the system from the company or organizational perspective and the purpose of the system; its goal is quite well specified, the goals of its operators, the users, might be much less clear. And for the user it is not enough that the function is possible to use, it has to be better than the previous system or better than doing the task by hand (1, 2, 3).
It has to be better than the previous method…
This is where at least some of the problems with the software development failures is to be found. Usability is important, but the system also has to conform to the reality experienced by the users; it has to make their work more enjoyable, not more stressful or complicated. Just to give a few examples from failed systems:
The region health care in Gävleborg has now replaced the old system “Mellior” (which was in itself not exactly a very well-liked system), with a version of Cosmic (3). It would of course be expected that you replace a system with a better one? Unfortunately, the new system and not least the transfer from the previous system leaves a lot to desire. Some of these problems relate to specific work tasks, whereas others are affecting the more general aspects of the usage. At the units of child psychiatry, it was soon found that the system was not at all designed for their usage. For safety reasons, you are many times ordered to work in pairs on some patients, which turned out not to be possible to administer in the new system(3). There were also no default templates for the specific tasks in the units, and when asked they received the answer that the templates should arrive about two years (!) after the new system had been introduced. Until then, the notes and other information had to be handled “ad hoc”, using the templates that were aimed at other units.
After some “trying and terror” there were some more serious issues that were discovered. If the wrong command (that most of the personnel felt to be the most natural) was used, the patient records were immediately visible to anyone who had access to the system. Even worse, it also turned out that hidden identities were no longer… hidden. The names, personal numbers, addresses, telephone numbers and other sensitive data were all visible in plain sight (3). The same security and integrity problem was also found in the system for the administration of school tests (5). This happened although it would be quite natural to assume that there is a certain purpose of keeping people’s identities hidden and protected. Could it be because the specific requirements regulating the “hidden identity records” was forgotten or omitted?
Big Bang Introduction
One clear cause of system failure has been traced down to the actual introduction of the system in the workplace. Ken Eason (1988) wrote about the different ways a new system could be introduced. The most common was described under the quite accurate name “Big Bang Introduction”. It is also one of the most common ways we still do it. At a certain date and time, the new system is started and the old one is closed down. Sometimes the old system is still running since all existing data may not have been transferred to the new system. This is often not a surprise, since the transfer of data is often not regarded as “important”.
Data transfer
When the Cosmic system was introduced (3), the data was not transferred auztomatically, fortunately. Instead the data had to be transferred manually, but also with a certain additional extra work needed. The different data records had to be “updated” with a certain additional tagging system before being transferred, because otherwise all the records would be dumped together in an unordered heap of data. The unordered heap then had to be resorted again according to the previous, existing labels (which were in the records all the time).
The patient records are, among other things, also used for communication with the patients. However, it turns out that when messages are sent to patients through Cosmic, they don’t get sent at all, although the sending is acknowledged by the system. The messages can deal with anything, from calls for patient visits, information about lab results or information about therapeutic meetings. Now the medic personnel has to revert to looking up the addresses manually in the old system, and then send the messages to each patient directly.
Training
I already mentioned above that one reason for why a new computer system is being developed is to make the work more efficient. As we also found, the new systems not always flawless. But even if they had been flawless, there is the problem that the workplace can already be in an overstressed mode of working. The time needed for additional training in the new system is often not available when the new system is introduced. This means that either the personnel has to learn the new system on their spare time or at home after work, or not get enough training. In some cases (3, 5) the responsibility for the training is instead handed over to the IT-support groups, where this can become even worse, if the time of introduction is badly chosen.
Cosmic(3) was introduced in January, Ladok(4) was introduced in the middle of the fall term. Other systems have been introduced during summer, which might seem to be a good choice. However, December-January contain the Christmas/New Year breaks, where it is difficult to get enough personnel to manage normal work conditions. Summer holidays likewise. To imagine that it would be easy to get people to also train on the new systems during those times is of course ridiculous.
But mid-term? The time for the introduction of the Ladok(4) system was for some reason placed when the people at the student office has the most of things to do, namely when the results for all courses for the first part of the term are to be reported, in Ladok, and all with very short deadlines. This is again a recipe for a bad start on the use of a new system.
The fridge…?
If some food runs a risk of getting spoiled, we probably put it in the fridge, or even the freezer. But when software products run a risk of getting bad, where is the fridge or freezer? Well, the first thing we have to do, is to clean out the rotten stuff, even before we start finding ways of preserving the new projects that will be developed. Essentially, we have to start rethinking the usability requirements on the software we produce, and also look back, not only to what has worked before, but even more learn from the previous failures.
But most important is that we start to work with the Human Factors as guiding principles, and not just as “explanations for when people make fatal mistakes”. We know a lot about the human factors and how they shape our reactions. This post is already very long, so I guess I have to get back with part 3 of 2 dealing with these factors as part of the failed projects. While you are waiting I can recommend to take a look at the excellent book about “Human Errors” by James Reason (1990).
Illustrations are made by Lars Oestreicher, using MidJourney (v 6 and 7).
References
Eason, Ken (1988) Information Technology and Organisational Change. London ; New York: Taylor & Francis.
Reason, James. (1990) Human Error. New York, New York, USA: Cambridge University Press
“Something is rotten in the state of … ” well, at least in Sweden, and at least when it comes to software systems. There are a large number of failures adding up over the years. I can understand the problem we had in the 1960s and the 1970s, and I can even understand the Y2K phenomenon (which actually seems to fade in even computer scientists’ collective memory). Before the year 2000 we didn’t understand that the software was going to be so well designed (!) that it would survive into a year, when the year “00” was not an error message, but an actual number.
However, if we go back through the very short history of computing, we find that there were a large number of failures already from the beginning. Not only with computers, but the machines that were connected to the computers. Just take the example of the first ATM machines that were introduced. For some reason people seemed to become very absent-minded all of a sudden. They started to leave their banking cards in the machine over and over again. When this issue was investigated more thoroughly, it became clear that it was necessary to change the order of two actions in order to make the system better in this respect. Instead of “get the money first” and “retrieve card after that”, the trick was to “retrieve the card first” and “then get the money”. As simple as that, right.
Now this is no longer a problem, since we have this “touch” authorisation of everything you do. Just touch your card or even the phone to a small sensor and everything is fine. But just before this became more common, there was a small period of time when the ticket machines for the car parking were exchanged to a new, safer model. Apparently, it was now a requirement from the EU that the card should remain inserted during the whole operation (it was in fact held there by some special mechanism). Guess what happened? A large number of people became amnesiac again, leaving their cards in the slot. But this was not a surprise to some of us. No, we knew that this were to happen. And of course there was a good reason for this problem to reoccur — THE GOAL of using THE MACHINE!
When you go to an ATM or go to a ticket machine for a car park, you have a goal with this – namely to get money, or pay the parking fee. The card we use to pay is not a central part (unless the account is empty or the machine is broken) of the task, it is not as important as getting the money, or getting the parking paid. We KNOW this since the 1970s. But today, it seems, it’s not the users who suffer from bad memory; it’s the software developers turn.
Today we know quite a lot about human factors. Human factors are not bad, on the contrary. We know when they can cause a problem, but we also have quite good knowledge about how we can use the human factors constructively, so that they help people to do the right thing more or less by default. This does not mean that there is a natural, or obvious way to do something, but if we take the human factors into considerations, we can in fact predict if something is going to work or not.
This sounds simple, of course, but the problem is not just to change the order of two actions. It means to understand what we are good at, and also when the human factors can lead us the wrong way.
But how can we know all this? By looking back!
It is by looking back on all the bad examples that we should be able to start to figure out what can go wrong. And the list of bad (failed) examples has not grown shorter over the years, even after the Y2K chaos (which in fact should be called the “centennium bug” rather than the “millenium bug”). In the late winter last year we had a new version of the millium bug (or a similar event, at least). Two of the major grocery chains in Sweden (and one in New Zeeland) could not get their cashiers to work. The system was not working at all. Since the Swedish government has stressed “the cashless society” so hard, it had the effect that a large number of customers was unable to do the shopping that day.
So, what was the problem? Well, from the millenium bug we know that years can be very tricky entities. They should have four numbers, otherwise there can be problems. So far so good! However, the developer of this financial system didn’t make a proper estimation of the importance of the years in the system. It turned out, in the end, that the day when the system stopped working, was a day that didn’t exist. At least it did not exist in the minds of the developers, when they designed the system. But now and then, February 29 does indeed exist. Almost (every) every 4th is a year leap year, where February has an extra day attached.
The question is how this kind of bugs can enter the development process? The thing is that we can study a large number of single anecdotical accounts without drawing any wider conclusions from the examples. But if we instead look at the failures from a human factors perspective, there are many conclusions that we can draw. Most of these are very easy to understand, but oh, so difficult they seem to be to actually make anything out of. In part 2 of this post, I will dive deeper into some of the anecdotal examples, and make an attempt to generalize the reasoning for future references. (to be continued…).
I wrote earlier about the threats that are currently attacking our computer systems in the society, and we can also see that there are new attempts at increasing the security in the systems. However, there is an inherent problem in computer security, namely the transparency and usability of the systems. It seems that it is very difficult to create security systems that are easy to use. We have been used to writing our passwords on sticky notes and paste them on the screen, and we put our PIN codes on small paper notes in the wallet so that we will not forget them when we really need them. The reason for this is of course that the passwords, in order to be strong, have to be more than impossible to remember. Even worse is that in order to be really safe (according to the professional advice), you should have different passwords everywhere. And there are also all the many PIN codes to all the cards we have.
One important property within the human being is the delimitation of the memory. We have problems remembering meaningless things, such as the recommended password: “gCjn*wZEZK^gN0HGFg4wUAws”. So people tend to not have that kind of passwords, which of course leads to a decreased security. Well, in some sense we also solved this problem by adding two-step verification, i.e., the “if-you-don’t-have-your-phone-you-are-lost”-verification. This, of course, has to be interleaved with “find a motorcycle” or “find the traffic lights” games, to prove that you are not a robot (!).
Now it has become better, we have biometric security. We use the fingerprint or facial recognition methods. Only problem is that after a day of work in the garden, the fingerprints are no longer recognizable, and after a severe accident, the face may not look at all like yourself anymore, so you cannot call your family to say that you are OK. Well, at least it is safe, isn’t it?
Yes, but not when it comes to the current means for BankID, the virtual identification used in Sweden. Yes, of course it works when you want to log into your bank in order to handle your affairs. It is an accepted identification method. BUT not when you want to move your BankID to a new telephone! To do so, you now (after the last change) have to scan your passport or national ID-card. The most common means of identification, which in Sweden is your driver’s license, is on the other hand NOT accepted.
You might think that that should not be any problems, since everybody will surely have a passport today? But, no, that is not the case. As an anecdotal evidence I will relate my fathers situation:
My father just turned 90 years old. He is still a young man in an old body, so he has an iMac, an iPad, a laser printer, etc. at home. He is in fact a quite heavy tech user for his age. He also had an old smartphone that started to lose its battery charging, so he was given a new smartphone as one of the birthday presents. The transfer of the data went smoothly and without any hiccups, until it was time to use the BankID on the new phone. It was of course not transferred. Thus, we ordered a new BankID on his bank and signed it with his BankID on his new phone. But now…
Who is being excluded by the design?
My father decided to quit driving several years ago. However, he still kept his drivers license and even had it renewed without problems. Although being an ex-globetrotter he also reckoned that he needs no passport any more. So, when I asked him for an ID, he produced the drivers license. That did of course not work, although it is valid as identification in most other places. It was not an option to go to the bank and identify himself. They cannot validate the BankID. It has to be done through the web page and the app. Sorry!
So, now I have to take my father through the heavy cold and snow to the police station to have a new passport, which is only going to be used one single time, that is, in order to install the BankID. Where is the user friendly procedure in this?
I would think that my father is not the only person who is using the driver’s license as identification. I assume that many older people, for example, will have a similar problem when they need to get a new BankID (provided that they even use a smartphone).
Where is the human-friendly procedure for establishing the identity? Why can we, for example, no longer trust the people at the bank to identify a person with a valid identification and flick a switch to accept the ID? To make the issue a bit more general: Where has the consequence analysis gone when we make this kind of decisions? Or even better stated:
Who is going to be excluded by the new design or decision?
This post was actually started in late 2023, when the Swedish Church had become the victim of a cyberattack with ransomware, which took place November 22. The church organization at that time decided that it will not pay the ransom (in order not to make this a successful attack) but will instead recover the systems manually over time. However, this recovery takes a lot of time, and as long as the systems are not completely recovered, it is not possible to make any bookings for baptizing and weddings. In case of a funeral, it has still been possible to make a booking, but, the data had to be taken down using pen and paper (i.e., post-it notes).
We are very vulnerable if we only depend on our digital systems.
Head of information services at the Swedish church
In Sweden, the church has been separated from the government, but it is also still responsible for a number of national and regional bookkeeping services, like funerals. Also, a large number of people will still use the church services for baptizing and weddings, where in the latter case it also fulfills its role as an official administrative unit, in parallel with the weddings that are registered by the government. Suffice it to say that the church depends heavily on digital administration for its work. Consequently, some parts of the Swedish society also depends on the same computer systems being intact.
More attacks…
In 2024, there has now been a number of similar events, mostly through the use of ransomware, but also with overloading web servers. The systems affected this time have been in other organizations and governmental institutions. The most famous of them this time is probably the HR management system Primula, which is also used by the defense organizations and industries, among many others (including universities). This time the attacks are suspected to be made Russian hackers, possibly as part of a destabilization campaign as part of the ongoing war in Ukraine.
Again, the main issue is not that there have been attacks that have been successful, but rather that the backup systems are insufficient or, in most cases seemingly missing. Hopefully the systems will soon be up and running again, but if there is an attack on systems that are more central to the functions in society, then the problem is not only in small organizations, but may affect larger systems including systems for money transfers. Recently shops have been forced to close, when there have been longer problems with the money services.
In this context it is also important to point to the problem with paying. The Swedish Civil Contingencies Agency (MSB), which is responsible for helping society prepare for major accidents, crises and the consequences of war, recently sent out a message to the public, advising them to always have at list 2000 SEK in cash at home. The question is whether the society is prepared to revert to using cash money for the transactions. A large number of shops and services no longer accept cash as payment.
What now
When interviewed, the head of the information service for the Swedish church said that one lesson they have learned from this event is that they have to be less dependent on computer services than before. He did not specify how in any more detailed way, but the message was more or less clear: “We are very vulnerable if we only depend on our digital systems”. His conclusion is neither new, nor especially controversial. When our computer systems or the Internet fails, we are more or less helpless in many places. However, most of the time, the threats are envisioned in terms of disk crashes, physical damage or other similar factors. The increased risk of cyber attacks is not mentioned to the public to any larger extent.
We depend on our IT-support units to handle any possible interrupt as fast as possible, but the question is whether this is enough. Are there backups of the data? Are there backup systems that are ready to be launched in case the old system is failing? Are there backup non-computer based procedures that can replace the computer systems if there is a longer breakdown of the computer systems? Even if it is costly to maintain these backup systems/procedures, it is quite likely that we will need to add a higher level of security in order to not end up with a social disaster, where a large part of the society is essentially incapacitated.
What are the consequences?
We can just imagine what would happen if, as mentioned above, the central systems for bank transfers fails badly or gets “cyber-kidnapped”. Credit cards will not work, neither will mobile money transfers or other electronic payment options. There will be no way to pay our bills, and we may not even get the bills at first hand. Probably even the ATM machines will cease to work, so that there is no possibility to get cash either. Imagine now that this failure will last for days and weeks. What are the consequences?
But we don’t have to look at this national disaster scenario. It is enough to think about what will happen if the computer systems in universities or other large organizations are attacked by cyber-criminals. Not to mention the effects on critical health care, where minutes and seconds can count. Do we have any possibilities to continue the work, reaching journals or other important documents, schedule meetings, planning operations and other important events? Are we really ready to start working on paper again, if necessary? I fear not!
With the current situation in the world, with wars and possible also challenges from deteriorating environmental factors, a lack of emergency plans for our digital systems may not only be causing serious problems, but may really turn out to be disastrous in case of any larger international crisis. Looking at what happens around the world currently, it is easy to see that the risk for cyber-attacks in international crisis situations has increased to a high degree. In many cases the (possible) plans on how to proceed are not known to people who work in the organizations. Is your work protected? Do you know what to do if the systems fail?
Unfortunately, we cannot continue to hope that “this will never happen”. Even if the most extreme of the possible scenarios may not happen, we are still very vulnerable to attacks, e.g., with ransomware or “Denial of service” from “normal cyber-criminals” and this can be just as bad on the local scene, when a whole organization is brought to a halt due to a computer system failing badly. Therefore we need to be acting proactively in order to not be stuck if/when the systems fail. Because, it is quite certain that they will fail at some point of time.
And how will YOUR organization handle that kind of situation? Do YOU know?
Information Technology is now being developed in a pace which is almost unbelievable. This is of course not always visible in the shape of computers, but also in the form of embedded technology, for example, in cars, home assistants, phones and so on. Much of this development is currently either driven by pure curiosity, or to cater for some perceived (sometimes imagined) user need. Among the former we may count the first version of the chatbots, where the initial research was mostly looking at how very large language models could be created. Once people became aware of the possibilities, that created a need for a service driven by the results, resulting in the new tools that are now being developed as a result.
Among the latter versions we have the development in the car industry as one example. Security has been a key issue among both drivers and car manufacturers for a long time. Most, if not all new cars today are equipped with intelligent non-locking brakes, anti-spin regulators, and even sensors that will support the driver in not crossing the lane borders involuntarily. The last feature is in fact more complex than might be thought at the beginning. Any course correction must be made in such a way that the driver feels that he or she is still in control of the car. The guiding systems have to interact seamlessly with the driver.
But there is one other ongoing development according to the latter version, which we can already see will have larger consequences for the society and for people in general. This development is also always announced as being of primary importance for the general public (at least for people with some financial funds). This is a product that resides at the far end of the ongoing development of car security systems. I am talking about the development of self-driving cars. The current attempts are still not successful enough to allow these cars to be let completely free in the normal traffic.
There are, however, some positive examples already, such as autonomous taxis in Dubai, and there are several car-driving systems that almost manage to behave in a safe manner. This is still not enough, as there have been a number of accidents with cars running in self-driving mode. But even when the cars become safe enough, one of the main remaining problems is the issue of responsibility. Who is responsible in the event of an accident? Currently, the driver is in most cases still responsible, since the law says that you cannot cease being aware of what happens in the surroundings. But, we are rapidly going towards a future where self driving cars may finally be a reality.
Why do we develop self-driving cars?
Enters the question: “Why?”. As a spoil sport I actually have to ask, why do we develop self driving cars? In the beginning, there was, of course, the curiosity aspect. There were competitions where cars were set to navigate long distances without human interception. But now, it seems to become more of a competition factor between car manufacturers. Who will be the first car producer that will cater for “the lazy driver who does not want to drive”?
It is, in fact, quite seldom that we hear any longer discussions about the target users of self-driving cars. For whom are they being developed? For the rich lazy driver? If so, that is in my opinion a very weak motivation. Everybody will of course benefit from a safer driving environment, and when (if) there is a time when there will only be self driving cars in the streets, it might be good for everybody, including cyclists and pedestrian. One other motivation mentioned has been that there are people who are unable to get a driver’s license, who would now be able to use a car.
But there is one group (or rather a number of groups) of people who would really benefit from this development when it is progressing further. Who are these people? Well, it is not very difficult to see that a group of people who would benefit the most of having self driving cars are people with severe impairments, and not least people with severe visual impairments. Today, blind people (among many others) are completely dependent on other people for their transport. In a self driving car, they could instead be free to go anywhere, anytime, just like everyone else today (if you have a valid driver’s license). This is in one sense the definition of freedom, as an extension of independence.
Despite this, we never hear this as an argument for the development of this fantastic supportive tool (as in fact, it could be). It is, as mentioned above, mostly presented as an interesting feature for techno-nerdy, rich and lazy drivers, who do not want to take the effort of driving themselves. Imagine what would happen if we could motivate this research from the perspective of supportive tools. Apart from raising the hope for millions of people who cannot drive, there would as a result also be millions of potential, eager new buyers only in the category of people who are blind or who have severe visual impairments. Adding to this also the possibility for older people who now have to stop driving due to age-related problems, who can now use the car much longer to a great personal benefit.
The self-driving car is indeed a very important supportive tool, and therefore I strongly support the current development!
This is, however, just one case among many others, on how we can motivate research also as a development of supportive tools. We just have to see the potentials in the research. Artificial Intelligence methods will allow us to “see” things without the help of our eye, make prostheses that move by will, and support people with dyslexia to read and write texts in a better way.
All it takes is a little bit of thinking outside of the box, some extra creativity, and, of course good knowledge about impairments and about the current rapid developments within (Information) Technology.
The education conference Frontiers in Education (FIE) 2023 was held in College Station, Texas. It is a quite large conference, and there were many tracks during the three days that the conference was on. College station is situated between Dallas and Houston, and it is a, well, lets say interesting city, and incorporates another apparently a bit older city, Bryant, in the close vicinity. There was not that much time for sight-seeing so it was mainly the road from the hotel to the conference centre that became the major view during the conference.
The conference offered a large number of very interesting presentations and I did in fact not sit through any bad or boring presentations, Before the main conference there was also one day of workshops, as usual so many that it was difficult to chose one of them. I attended one on inclusive mentoring, which was very inspiring as a supervisor/mentor in general . I am of course very happy to find that there were quite a few presentations, work shops and special sessions that dealt with the issue of inclusion of students on various levels.
The special session on “Disabled Students in Engineering” was held by four Ph.D. students, and was very well prepared, rendering lots of inspiration for the teaching. The organizers also shared very good working material, which can be reused, e.g., in course seminars (I have just started a 15 credit course on non-excluding design).
All in all, the conference felt well worth the effort and time spent. It is always a good feeling when you return home and feel inspired, and just long for putting all the experiences at work in your own teaching. I have already added several new ideas to the course, and I think that this will improve the course a lot.
Still, maybe the most inspiring part of the conference was the (positive and constructive) critique I received on my presentation and paper: “New Perspectives on Education and Examination in the Age of Artificial Intelligence,” which I almost wanted to retitle as “Old perspectives…” since it looks back at older forms of examination, where there was a closer connection between teacher and student. This closer connection and the way it is achieved does make it more difficult for the student to “cheat” or use the AI chat bots.
An old Greek teacher and his student discussing some interesting problem during the examination
This post is already long enough, so I will not present the paper in any more detail here, but should you want to have a copy of the paper, please contact me with an email. You are also free to comment/criticize this post in the comment section below.
Note: This is a long article, written from a very personal take on Artificial Intelligence.
The current hype word seems to be “Artificial Intelligence” or in its short form “AI. If one is to believe what people say, AI is now everywhere, threatening everything from artists to industrial workers. There is even the (in)famous letter, written by some “experts” in the field, calling for an immediate halt to the development of new and better AI systems. But nothing really happened after that, and now the DANGER is apparently hovering over us all. Or is it?
Hint: Yes, it is, but also not in the way we might think!
The term “Artificial Intelligence” has recently been watered out in media and advertisements, so that the words almost don’t mean anything anymore. Despite this, the common ideas seem to be that we should 1) either be very, very afraid, or 2) hurriedly adapt to the new technology (AI) as fast as possible. But why should we be afraid at all, and for what? When asked, people often reply that AI will replace everybody at work, or that evil AI will take over anything from governments to the world as a whole. This latter is of course also a common theme for science fiction books and movies. Still, neither of these are really good reasons to fear the current development. But in order to understand why this is so, we need to go back to the historical roots of Artificial Intelligence.
What do we Mean by AI, then?
Artificial Intelligence started as a discipline in 1956 during a workshop at Dartmouth College, USA. During the discipline development, a distinction between two directions formed, that between strong and weak AI. Strong AI aims at replicating a human type of intelligence, whereas weak AI aimed at develop computations methods or algorithms that made use of ideas gained from Human Intelligence (often for specific areas of computation). Neural networks are, for example, representative of the weak AI directions. Today, strong AI is also referred to as AGI (Artificial General Intelligence), meaning a non-specialized artificial agent.
But in the 1950:s and 1960:s computers were neither as fast, nor as large as the current computers, which at that time imposed severe limitations on what you were able to do within the field. A large amount of work was theoretical, but there were some interesting implementations, such as Eliza, SHRDLU and not least Conceptual Dependencies (I have chosen these three examples carefully, since each of these poses some interesting properties with respect to AI, and I will explain this in the following and then follow up on the introduction):
Conceptual Dependencies : Conceptual Dependencies is an example of a very successful implementation of an artificial system with a very interesting take on knowledge representation. The system was written in the programming language LISP, and attempted to extract the essential knowledge that hid in the texts. The result was a conceptual dependency network, that could then be used successfully to summarize news articles on certain topics (the examples were taken from natural disasters and airplane hijacking). There were also attempts to make the system produce small (children’s) stories. All in all, the problem was that the computers were too small to be practically useful.
SHRDLU : SHRDLU was a virtual system that worked by having a small robot manipulating geometric shapes in a 3D modelling world. It was able to reason about the different possible or impossible moves, for example, that it is not possible to put a cube on top of a pyramid, but it is OK to do the reverse. The problem with SHRDLU was that there were some bugs in the representation and the reasoning, which ended in that it was pointed out that the examples shown were most likely preselected and did not display any general reasoning capabilities.
Eliza : The early chatbot Eliza is probably most known as the “Computer Psychologist”. It was able to keep up a conversation with a human for some time, pretending to be a Psychologist and it did so well that it was enough to actually convince some people that it was a real Psychologist behind the screen. “But, hold it!” someone may say here, “Eliza was not a real artificial intelligence! It was a complete fake!”. And yes, you would be perfectly right here. Eliza was a fraud, not so that it wasn’t a computer program, but in that it was faking the “understanding” of what the user wrote. But this is exactly the point with mentioning Eliza here. A intelligence-like behaviour may fool many, even though it does not have any “intelligent system” under the hood.
What can we Learn from AI History?
The properties of these three historical systems that I would like to point to in more detail are as follows:
Conceptual dependencies: AI needs some kind of knowledge representation. At least some basic knowledge must be stored in some way as a basis for the interpretation of the prompts.
SHRDLU : An artificial agent needs to be able to do some reasoning about this knowledge. Knowledge representation is only useful if it possible to use it for reasoning and possible generation of new data.
Eliza : Not all AI-like systems are to be considered to be real Artificial Intelligence. In fact Joseph Weizenbaum created Eliza in order to prove exactly how easy it was to emulate some “intelligent behaviour”.
To start with these three examples also have one interesting common property, namely that they are transparent since the theory and implementations have been made public. This is actually a major problem with many of the current generative AI agents, since they are based on large amounts of data, the source listings of which are not publicly available.
The three examples above also point to additional problems with the generative modelling approaches to AI (those that are currently considered so dangerous). In order to become an AGI (artificial general intelligence) it is most likely that there needs to be some kind of knowledge base, and an ability to reason about this knowledge. We could in fact regard the large generative AI agents as very advanced versions of Eliza, in some cases also enhanced with search abilities in order to give better answers, but as a matter of fact they don’t really produce “new” knowledge, just phrases that are the most probable continuations of the texts in the prompts. Considering the complexity of languages this is in itself no small feat, but it is definitely not a form of intelligent reasoning.
The similarity to Eliza is increased by the way the answers are given to a person, in that they are given in a very friendly form, even having the system apologize when it is pointed out that the answer it has given is not correct. This conversational style of interaction can easily fool users who are less knowledgeable about computers that there is a genie in the system, which is very intelligent and (very close to) a know-it-all. More about this problem later in this post.
Capabilities of and Risks with Generative AI?
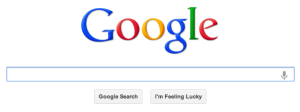
The main problem that has arisen is that the generative AI systems cannot produce any real novelties, since the answers are based on (in the best case, extrapolation of) existing texts (or pictures). Should they by any chance produce new knowledge, there is no way to know whether this “new knowledge” is correct or not! And here is where, in my opinion, the real danger with generative AI lies. If we ask for information we either get correct “old” information, or new information which we cannot know whether it is correct or not. And we are only given one single answer per question. In this sense the chatbots could be compared to the first version of Google search, which contained a button marked “I’m feeling lucky!”, an option which just gave you one single answer, and not as now hundreds of pages to look through.
Googles search page with the “I’m feeling lucky!”-button, which has now been removed.
The chatbots also provide single answers (longer of course), but in Eliza manner wrapped in a conversational style that is supposed to convince the user that the answer is correct. Fortunately (or not?), the answers are often quite correct, so they will in most cases provide both good and useful information. However, all results still need to be “proof-read” in order to guarantee the validity of the contents. Thus, the users will have to apply critical thinking and reasoning to a high extent when using the results. Paradoxically, the better the systems become, i.e., the more of the results that are correct, the more we need to check the results in detail, especially when critical documents are to be produced where an error may have large consequences.
Impressive systems for sure!
Need we be worried about the AI development, then? No, today there is no real reason to worry about the development as such, but we need to be more concerned about the common usage of the results from AI systems. It is necessary to make sure that the users do understand that chatbots are not intelligent in the sense we normally think. They are good at (re-)producing text (and images), which most of the time make them very useful supportive tools for writers and programmers, for example. Using the bots to create text that can be used as a base for writing a document or an article is one interesting example of where this kind of systems will prove to be very important in the future. It will still be quite some time before they will be able to write an exiting and interesting novel, without the input and revision of a human author. Likewise, I would be very hesitant about using a chatbot to write a research article, or even worse, a text book in any topic. These latter usages will definitely require a significant amount or proof-reading, fact-checking and not least rewriting, before being released.
The AI systems that are under debate now are still very impressive creations, of course, and they manifest a significant progress in the engineering of software. The development of these systems is remarkable, and they have a potential to become very important in society, but they do not really produce really intelligent behaviour. The systems are very good statistical language generators, but with a very, very advanced form of Eliza at the controls
The future?
Will there be AGI, or strong AI beings in the future? Yes, undoubtedly, but this will take a long time still (I am prepared to be the laughing stock in five years, if they arrive. And these systems will most likely be integrated with the generative AI we have to day for the language management. Still, we will most likely not be able to get there, as long as we forget about the use of some kind of knowledge network underneath. It might not be in the classic form as mentioned above, but it seems that knowledge and reasoning strategies, rather than statistical models has to form some kind of underlying technology.
How probable is this different development path leading to strong AI, or AGI systems? Personally, I think it is quite probable and it seems to be doable, but I am also very curious about how the development will proceed over time. I would be extremely happy if an AGI could be born in my life time (being 61 at the time of writing).
And hopefully these new beings will be in the shape of benevolent, very intelligent agents, that can cooperate with humans in a constructive way. I still have the hope. Please feel free to add your thought in the comments below.
Last Friday, I was interviewed by the Swedish television (the local Uppland channel) about the reasons for this and the possible dangers with the application from a security perspective. The interview can be found here but it is only in Swedish. Therefore I will describe the problem in this post as well.
The municipality of Uppsala, together with a large number of other public actors (also in many other countries) have recently prohibited the use of TikTok on the work spade. Apart from that some people might think that there are very limited reasons to why you should need access to TikTok on your mobiles at all during your work, why would you prohibit the use of TikTok, when you can still use Youtube, Instagram and Facebook? What is different with TikTok?
There are actually some reasons for this, both the prohibition and the differences between the application. TikTok is an application that allows the users to record short videos (max 3 min) and publish these on the TikTok platform. This has become very popular among, above all, young people. There is also an ongoing critical discussion about the social aspects of the TikTok application, but it is not part of this post.
When the application is installed, it asks the user for permission to access photo and video storage, the camera and the microphone, which is of course quite reasonable, since the purpose of the app is exactly to record videos and store them in the user’s phone. However, it also asks for access to the contact lists, and the current location when used. And here is one of the problems, namely that this data is given by the user to an application we know very little about. But, one may object, this data is not dangerous, we give it to almost any of the social media applications (actually, that might be something we should not do either, without some consideration).
The data the users provide is, however, actually not that innocent as it might seem at first sight. If the application can collect the data as mentioned above, the data might form a much bigger collection of “innocent” data, which is not as innocent anymore. It contains your contacts, the places where you have been, and also when you where there. If the data of different people are correlated on the whole data set, there might be patterns that could show interesting things for people who are specifically interested. It could for example show regular visits to certain locations, or even that you meet some people regularly. Still, who would be interested of this information? Not everything might be interesting, but suppose that you are engaged in a civil defense organization. Then the meeting places, the people you meet at those meetings, and who these people meet in other contexts might be very important information for a possible enemy. So, there are quite a few people in a city that could be of interest in this kind of analysis.
But, as mentioned above, this information is provided to many different applications, so why has TikTok been singled out like this? Well, there is one additional argument for this, namely that it is very important that we know where the information is going in the larger perspective. This is where the history of TikTok becomes relevant. TikTok is owned by the Chinese company ByteDance, one of the biggest startup companies in the world, and this is where the main problem starts. The statement in the Privacy Policy gives an indication (my boldface added):
We may disclose any of the Information We Collect to respond to subpoenas, court orders, legal process, law enforcement requests, legal claims, or government inquiries, and to protect and defend the rights, interests, safety, and security of the Platform, our affiliates, users, or the public. We may also share any of the Information We Collect to enforce any terms applicable to the Platform, to exercise or defend any legal claims, and comply with any applicable law.
TiKToK Privacy Policy
The text in boldface provides a key to the problems. The data can be released in certain situations, which are not under our control. In 2017 China implemented a law that compels companies to turn over personal data relevant to China’s security. The question is then what this data might be. Depending on the situation, information pertaining other countries’ military and/or civil defenses might be very relevant to another country. The company can, through its mother company be forced to hand out any information under the conditions mentioned.
What are the odds? It is difficult to say, of course. However, since TikTok is not crucial to the work in public organizations, there is no reason even to take the chances. Especially in the current situation where there is such unrest over most of the world, there is definitely a reason for being careful in general with the handing out of data.
But, there are also some drawbacks with the general ban on the application. As mentioned above, the application is mostly used by young people. This also means that the proper use of the application can become an entry point to different youth groups, which could be invaluable to certain groups in the municipality, such as social workers, schools, and not least libraries. The libraries have used the application for some time to spread information to young people under the hashtag #BookTok, which allegedly has been very popular. This will now become difficult to handle with the current ban. Of course there may be ways around this ban, but in my opinion it all goes to show that a ban on an application like this has to be carefully considered, and that there should be an awareness of that there could be cases where there has to be exceptions. And, not least, there is a need for more information to potential users of social media about the possible risks that follow the usage.
To quote a famous detective in a famous TV-series:
In our research group, we study the relationships and dynamics of Human, Technology, and Organisation (HTO) to create knowledge that supports sustainable development and utilization of ICT.